Inference Batcher¶
This docs explains on how batch prediction for any ML frameworks (TensorFlow, PyTorch, ...) without decreasing the performance.
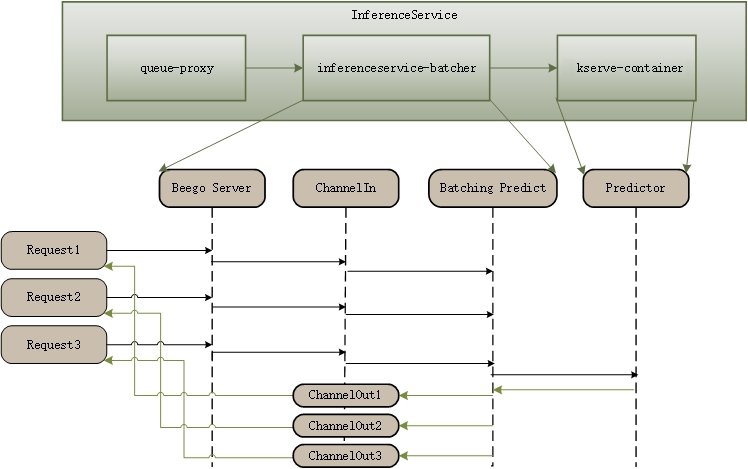
This batcher is implemented in the KServe model agent sidecar, so the requests first hit the agent sidecar, when a batch prediction is triggered the request is then sent to the model server container for inference.
-
We use webhook to inject the model agent container in the InferenceService pod to do the batching when batcher is enabled.
-
We use go channels to transfer data between http requset handler and batcher go routines.
-
Currently we only implemented batching with KServe v1 HTTP protocol, gRPC is not supported yet.
-
When the number of instances (For example, the number of pictures) reaches the
maxBatchSizeor the latency meets themaxLatency, a batch prediction will be triggered.
Example¶
We first create a pytorch predictor with a batcher. The maxLatency is set to a big value (5000 milliseconds) to make us be able to observe the batching process.
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "pytorch-cifar10"
spec:
predictor:
minReplicas: 1
timeout: 60
batcher:
maxBatchSize: 32
maxLatency: 5000
pytorch:
modelClassName: Net
storageUri: "gs://kfserving-samples/models/pytorch/cifar10/"
-
maxBatchSize: the max batch size for triggering a prediction. -
maxLatency: the max latency for triggering a prediction (In milliseconds). -
timeout: timeout of calling predictor service (In seconds).
All of the bellowing fields have default values in the code. You can config them or not as you wish.
-
maxBatchSize: 32. -
maxLatency: 5000. -
timeout: 60.
kubectl create -f pytorch-batcher.yaml
We can now send requests to the pytorch model using hey.
The first step is to determine the ingress IP and ports and set INGRESS_HOST and INGRESS_PORT
MODEL_NAME=pytorch-cifar10
INPUT_PATH=@./input.json
SERVICE_HOSTNAME=$(kubectl get inferenceservice pytorch-cifar10 -o jsonpath='{.status.url}' | cut -d "/" -f 3)
hey -z 10s -c 5 -m POST -host "${SERVICE_HOSTNAME}" -H "Content-Type: application/json" -D ./input.json "http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/$MODEL_NAME:predict"
The request will go to the model agent container first, the batcher in sidecar container batches the requests and send the inference request to the predictor container.
Note
If the interval of sending the two requests is less than maxLatency, the returned batchId will be the same.
Expected Output
Summary:
Total: 10.6268 secs
Slowest: 1.6477 secs
Fastest: 0.0050 secs
Average: 0.1006 secs
Requests/sec: 48.1800
Total data: 167424 bytes
Size/request: 327 bytes
Response time histogram:
0.005 [1] |
0.169 [447] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.334 [30] |■■■
0.498 [7] |■
0.662 [10] |■
0.826 [3] |
0.991 [6] |■
1.155 [5] |
1.319 [1] |
1.483 [1] |
1.648 [1] |
Latency distribution:
10% in 0.0079 secs
25% in 0.0114 secs
50% in 0.0398 secs
75% in 0.0867 secs
90% in 0.2029 secs
95% in 0.5170 secs
99% in 1.1428 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0000 secs, 0.0050 secs, 1.6477 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0000 secs
req write: 0.0002 secs, 0.0001 secs, 0.0004 secs
resp wait: 0.1000 secs, 0.0046 secs, 1.6473 secs
resp read: 0.0003 secs, 0.0000 secs, 0.0620 secs
Status code distribution:
[200] 512 responses