ModelMesh Serving¶
Multi-model serving with ModelMesh is an alpha feature added recently to increase KServe’s scalability. Please assume that the interface is subject to changes.
Overview¶
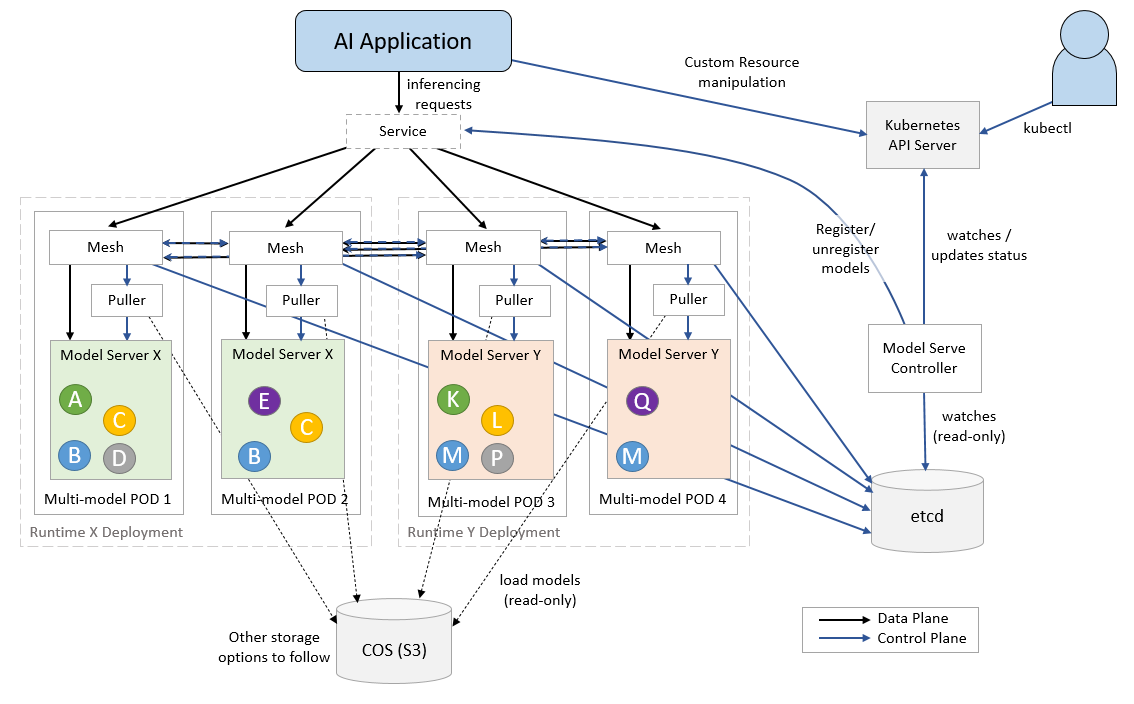
ModelMesh Serving is a Kubernetes-based platform for realtime serving of ML/DL models, optimized for high volume/density use cases. Utilization of available system resources is maximized via intelligent management of in-memory model data across clusters of deployed Pods, based on usage of those models over time.
Leveraging existing third-party model servers, a number of standard ML/DL model formats are supported out-of-the box with more to follow: TensorFlow, PyTorch ScriptModule, ONNX, scikit-learn, XGBoost, LightGBM, OpenVINO IR. It's also possible to extend with custom runtimes to support arbitrary model formats.
The architecture comprises a controller Pod that orchestrates one or more Kubernetes "model runtime" Deployments which load/serve the models, and a Service that accepts inferencing requests. A routing layer spanning the runtime pods ensures that models are loaded in the right places at the right times and handles forwarding of those requests.
The model data itself is pulled from one or more external storage instances which must be configured in a Secret. We currently support only S3-based object storage (self-managed storage is also an option for custom runtimes), but more options will be supported soon.
ModelMesh Serving makes use of two core Kubernetes Custom Resource types:
ServingRuntime- Templates for Pods that can serve one or more particular model formats. There are three "built in" runtimes that cover the out-of-the-box model types, custom runtimes can be defined by creating additional ones.Predictor- This represents a logical endpoint for serving predictions using a particular model. The Predictor spec specifies the model type, the storage in which it resides and the path to the model within that storage. The corresponding endpoint is "stable" and will seamlessly transition between different model versions or types when the spec is updated.
The Pods that correspond to a particular ServingRuntime are started only if/when there are one or more defined Predictors that require them.
We have standardized on the KServe v2 data plane API for inferencing, this is supported for all of the built-in model types. Only the gRPC version of this API is supported in this version of ModelMesh Serving, REST support will be coming soon. Custom runtimes are free to use gRPC Service APIs for inferencing, including the KSv2 API.
System-wide configuration parameters can be set by creating a ConfigMap with name model-serving-config.
Components¶
Core components¶
- ModelMesh Serving - Model serving controller
- ModelMesh - ModelMesh containers used for orchestrating model placement and routing
Runtime Adapters¶
- modelmesh-runtime-adapter - the containers which run in each model serving pod and act as an intermediary between ModelMesh and third-party model-server containers. It also incorporates the "puller" logic that is responsible for retrieving the models from storage
Model Serving Runtimes¶
- triton-inference-server - NVIDIA's Triton Inference Server
- seldon-mlserver - Python-based inference server
- openVINO-model-server - OpenVINO Model Server
KServe integration¶
Note that the integration of KServe with ModelMesh is still in an alpha stage and there are still features like explainers that do not yet work when deploying on ModelMesh.
In any case, ModelMesh Serving supports deploying models using KServe's InferenceService interface. ModelMesh Serving also supports transformer use cases in which the transformers and predictors are separately deployed by KServe and ModelMesh controllers. An example of ModelMesh transformer can be found here.
While ModelMesh Serving can handle both its original Predictor CRD and the KServe InferenceService CRD, there is work being done to
eventually have both KServe and ModelMesh converge on the usage of InferenceService CRD.
Install¶
For installation instructions check out here.
Learn more¶
To learn more about ModelMesh, check out the documentation.