Data Plane¶
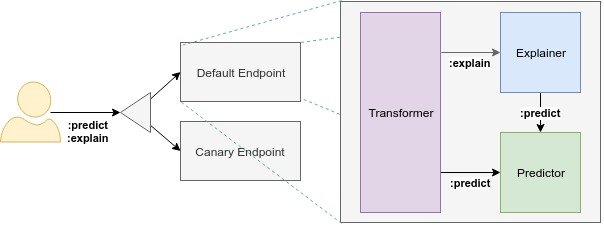
The InferenceService Data Plane architecture consists of a static graph of components which coordinate requests for a single model. Advanced features such as Ensembling, A/B testing, and Multi-Arm-Bandits should compose InferenceServices together.
Introduction¶
KServe's data plane protocol introduces an inference API that is independent of any specific ML/DL framework and model server. This allows for quick iterations and consistency across Inference Services and supports both easy-to-use and high-performance use cases.
By implementing this protocol both inference clients and servers will increase their utility and portability by operating seamlessly on platforms that have standardized around this API. Kserve's inference protocol is endorsed by NVIDIA Triton Inference Server, TensorFlow Serving, and TorchServe.
Note: Protocol V2 uses /infer instead of :predict
Concepts¶
Component: Each endpoint is composed of multiple components: "predictor", "explainer", and "transformer". The only required component is the predictor, which is the core of the system. As KServe evolves, we plan to increase the number of supported components to enable use cases like Outlier Detection.
Predictor: The predictor is the workhorse of the InferenceService. It is simply a model and a model server that makes it available at a network endpoint.
Explainer: The explainer enables an optional alternate data plane that provides model explanations in addition to predictions. Users may define their own explanation container, which configures with relevant environment variables like prediction endpoint. For common use cases, KServe provides out-of-the-box explainers like Alibi.
Transformer: The transformer enables users to define a pre and post processing step before the prediction and explanation workflows. Like the explainer, it is configured with relevant environment variables too. For common use cases, KServe provides out-of-the-box transformers like Feast.
Data Plane V1 & V2¶
KServe supports two versions of its data plane, V1 and V2. V1 protocol offers a standard prediction workflow with HTTP/REST. The second version of the data-plane protocol addresses several issues found with the V1 data-plane protocol, including performance and generality across a large number of model frameworks and servers. Protocol V2 expands the capabilities of V1 by adding gRPC APIs.
Main changes¶
- V2 does not currently support the explain endpoint
- V2 added Server Readiness/Liveness/Metadata endpoints
- V2 endpoint paths contain
/instead of: - V2 renamed
:predictendpoint to/infer - V2 allows for model versions in the request path (optional)
V1 APIs¶
| API | Verb | Path |
|---|---|---|
| List Models | GET | /v1/models |
| Model Ready | GET | /v1/models/<model_name> |
| Predict | POST | /v1/models/<model_name>:predict |
| Explain | POST | /v1/models/<model_name>:explain |
V2 APIs¶
| API | Verb | Path |
|---|---|---|
| Inference | POST | v2/models/<model_name>[/versions/<model_version>]/infer |
| Model Metadata | GET | v2/models/<model_name>[/versions/<model_version>] |
| Server Readiness | GET | v2/health/ready |
| Server Liveness | GET | v2/health/live |
| Server Metadata | GET | v2 |
| Model Readiness | GET | v2/models/<model_name>[/versions/ |
** path contents in [] are optional
Please see V1 Protocol and V2 Protocol documentation for more information.