Announcing: KServe v0.9.0¶
Today, we are pleased to announce the v0.9.0 release of KServe! KServe has now fully onboarded to LF AI & Data Foundation as an Incubation Project!
In this release we are excited to introduce the new InferenceGraph feature which has long been asked from the community. Also continuing the effort from the last release for unifying the InferenceService API for deploying models on KServe and ModelMesh, ModelMesh is now fully compatible with KServe InferenceService API!
Introduce InferenceGraph¶
The ML Inference system is getting bigger and more complex. It often consists of many models to make a single prediction. The common use cases are image classification and natural language multi-stage processing pipelines. For example, an image classification pipeline needs to run top level classification first then downstream further classification based on previous prediction results.
KServe has the unique strength to build the distributed inference graph with its native integration of InferenceServices, standard inference protocol for chaining models and serverless auto-scaling capabilities. KServe leverages these strengths to build the InferenceGraph and enable users to deploy complex ML Inference pipelines to production in a declarative and scalable way.
InferenceGraph is made up of a list of routing nodes with each node consisting of a set of routing steps. Each step can either route to an InferenceService or another node defined on the graph which makes the InferenceGraph highly composable. The graph router is deployed behind an HTTP endpoint and can be scaled dynamically based on request volume. The InferenceGraph supports four different types of routing nodes: Sequence, Switch, Ensemble, Splitter.
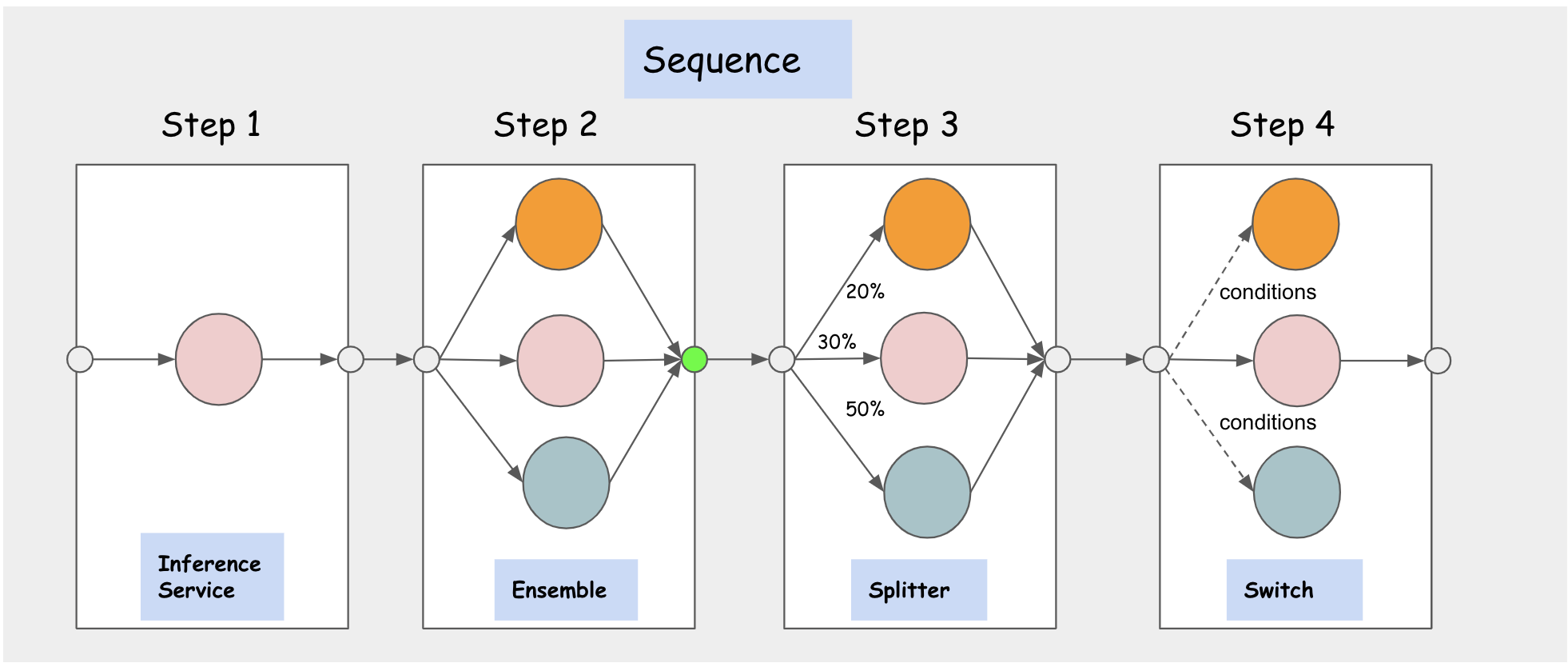
- Sequence Node: It allows users to define multiple
StepswithInferenceServicesorNodesas routing targets in a sequence. TheStepsare executed in sequence and the request/response from the previous step and be passed to the next step as input based on configuration. - Switch Node: It allows users to define routing conditions and select a
Stepto execute if it matches the condition. The response is returned as soon as it finds the first step that matches the condition. If no condition is matched, the graph returns the original request. - Ensemble Node: A model ensemble requires scoring each model separately and then combines the results into a single prediction response. You can then use different combination methods to produce the final result. Multiple classification trees, for example, are commonly combined using a "majority vote" method. Multiple regression trees are often combined using various averaging techniques.
- Splitter Node: It allows users to split the traffic to multiple targets using a weighted distribution.
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "cat-dog-classifier"
spec:
predictor:
pytorch:
resources:
requests:
cpu: 100m
storageUri: gs://kfserving-examples/models/torchserve/cat_dog_classification
---
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "dog-breed-classifier"
spec:
predictor:
pytorch:
resources:
requests:
cpu: 100m
storageUri: gs://kfserving-examples/models/torchserve/dog_breed_classification
---
apiVersion: "serving.kserve.io/v1alpha1"
kind: "InferenceGraph"
metadata:
name: "dog-breed-pipeline"
spec:
nodes:
root:
routerType: Sequence
steps:
- serviceName: cat-dog-classifier
name: cat_dog_classifier # step name
- serviceName: dog-breed-classifier
name: dog_breed_classifier
data: $request
condition: "[@this].#(predictions.0==\"dog\")"
Currently InferenceGraph is supported with the Serverless deployment mode. You can try it out following the tutorial.
InferenceService API for ModelMesh¶
The InferenceService CRD is now the primary interface for interacting with ModelMesh. Some changes were made to the InferenceService spec to better facilitate ModelMesh’s needs.
Storage Spec¶
To unify how model storage is defined for both single and multi-model serving, a new storage spec was added to the predictor model spec. With this storage spec, users can specify a key inside a common secret holding config/credentials for each of the storage backends from which models can be loaded. Example:
storage:
key: localMinIO # Credential key for the destination storage in the common secret
path: sklearn # Model path inside the bucket
# schemaPath: null # Optional schema files for payload schema
parameters: # Parameters to override the default values inside the common secret.
bucket: example-models
Model Status¶
For further alignment between ModelMesh and KServe, some additions to the InferenceService status were made. There is now a Model Status section which contains information about the model loaded in the predictor. New fields include:
states- State information of the predictor's model.activeModelState- The state of the model currently being served by the predictor's endpoints.targetModelState- This will be set only whentransitionStatusis notUpToDate, meaning that the target model differs from the currently-active model.transitionStatus- Indicates state of the predictor relative to its current spec.modelCopies- Model copy information of the predictor's model.lastFailureInfo- Details about the most recent error associated with this predictor. Not all of the contained fields will necessarily have a value.
Deploying on ModelMesh¶
For deploying InferenceServices on ModelMesh, the ModelMesh and KServe controllers will still require that the user specifies the serving.kserve.io/deploymentMode: ModelMesh annotation.
A complete example on an InferenceService with the new storage spec is showing below:
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: example-tensorflow-mnist
annotations:
serving.kserve.io/deploymentMode: ModelMesh
spec:
predictor:
model:
modelFormat:
name: tensorflow
storage:
key: localMinIO
path: tensorflow/mnist.savedmodel
Other New Features:¶
- Support serving MLFlow model format via MLServer serving runtime.
- Support unified autoscaling target and metric fields for InferenceService components with both Serverless and RawDeployment mode.
- Support InferenceService ingress class and url domain template configuration for RawDeployment mode.
- ModelMesh now has a default OpenVINO Model Server ServingRuntime.
What’s Changed?¶
- The KServe controller manager is changed from StatefulSet to Deployment to support HA mode.
- log4j security vulnerability fix
- Upgrade TorchServe serving runtime to 0.6.0
- Update MLServer serving runtime to 1.0.0
Check out the full release notes for KServe and ModelMesh for more details.
Join the community¶
- Visit our Website or GitHub
- Join the Slack (#kserve)
- Attend our community meeting by subscribing to the KServe calendar.
- View our community github repository to learn how to make contributions. We are excited to work with you to make KServe better and promote its adoption!
Thank you for contributing or checking out KServe!
– The KServe Working Group