Inference Graph¶
Motivation¶
ML inference system is getting bigger and more complex, it often consists of many models to make a single prediction. The common use cases are image classification and nature language processing pipelines. For example, a face recognition pipeline may need to find the face area first and then compute the features of the faces to match the database; a NLP pipeline needs to run a document classification first then downstream named entity detection based on previous classification results.
KServe has the unique strength to build distributed inference graph: graph router autoscaling, native integration with individual InferenceServices, standard inference protocol for chaining models. KServe
leverage these strengths to build InferenceGraph and enable users to deploy complex ML inference pipelines to production in a declarative and scalable way.
Concepts¶
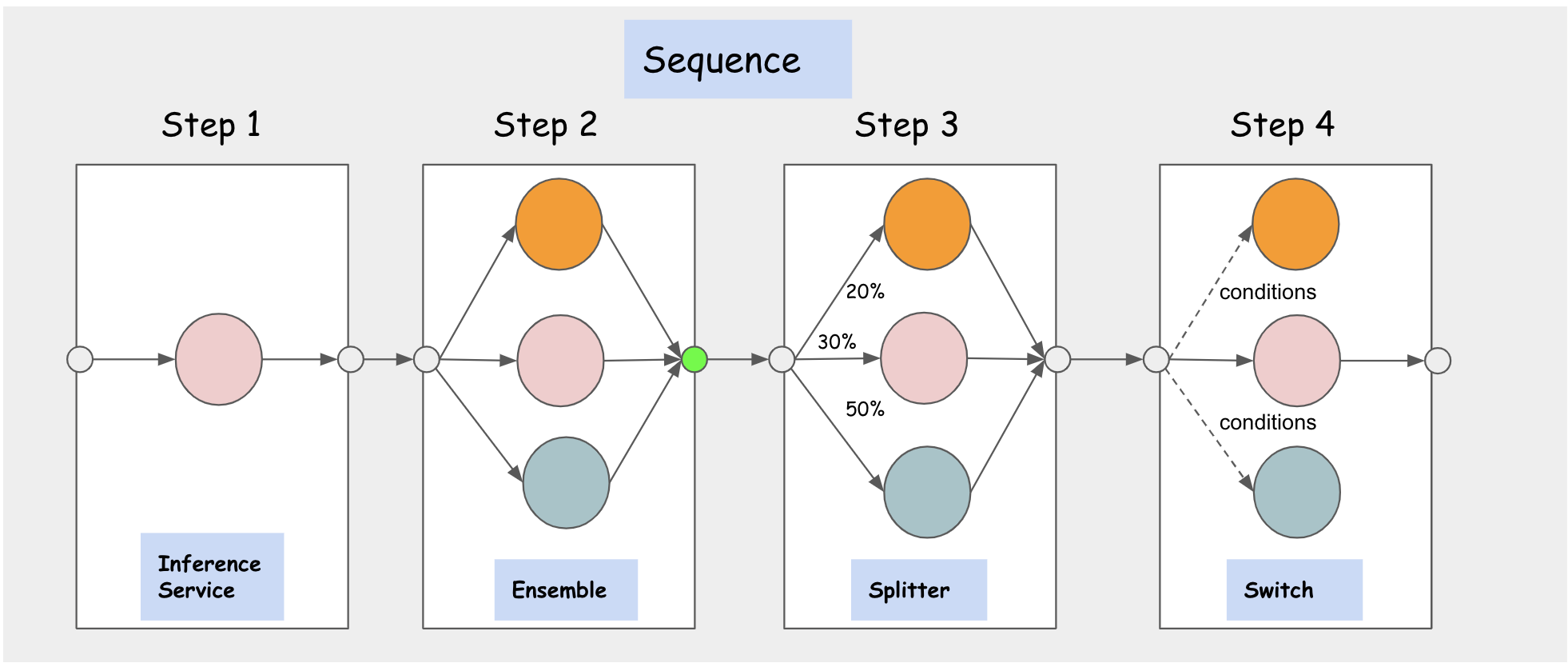
-
InferenceGraph: It is made up with a list of routing
Nodes, eachNodeconsists of a set of routingSteps. EachStepcan either route to anInferenceServiceor anotherNodedefined on the graph which makes theInferenceGraphhighly composable. The graph router is deployed behind an HTTP endpoint and can be scaled dynamically based on request volume. TheInferenceGraphsupports four different types of RoutingNodes: Sequence, Switch, Ensemble, Splitter. -
Sequence Node: It allows users to define multiple
StepswithInferenceServicesorNodesas routing targets in a sequence. TheStepsare executed in sequence and the request/response from previous step can be passed to the next step as input based on configuration. -
Switch Node: It allows users to define routing conditions and select a step to execute if it matches the condition, the response is returned as soon it finds the first step that matches the condition. If no condition is matched, the graph returns the original request.
-
Ensemble Node: A model ensemble requires scoring each model separately and then combining the results into a single prediction response. You can then use different combination methods to produce the final result. Multiple classification trees, for example, are commonly combined using a "majority vote" method. Multiple regression trees are often combined using various averaging techniques.
-
Splitter Node: It allows users to split the traffic to multiple targets using a weighted distribution.