From Serverless Predictive Inference to Generative Inference - Introducing KServe v0.13



Published on May 15, 2024
We are excited to unveil KServe v0.13, marking a significant leap forward in evolving cloud native model serving to meet the demands of Generative AI inference. This release is highlighted by three pivotal updates: enhanced Hugging Face runtime, robust vLLM backend support for Generative Models, and the integration of OpenAI protocol standards.
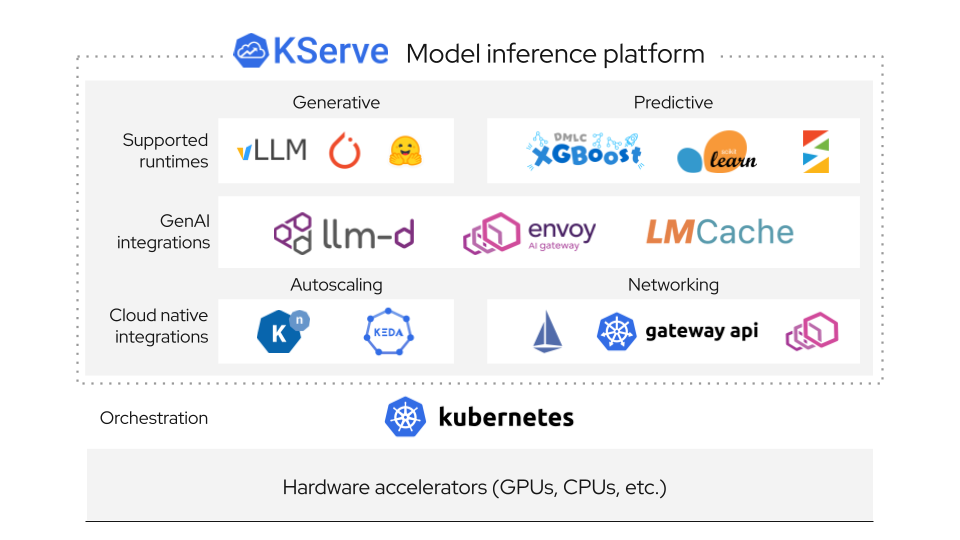
Below are a summary of the key changes.
🚀 Enhanced Hugging Face Runtime Support
KServe v0.13 enriches its Hugging Face runtime and now supports running Hugging Face models out-of-the-box. KServe v0.13 implements a KServe Hugging Face Serving Runtime, kserve-huggingfaceserver. With this implementation, KServe can now automatically infer a task from model architecture and select the optimized serving runtime. Currently supported tasks include sequence classification, token classification, fill mask, text generation, and text to text generation.
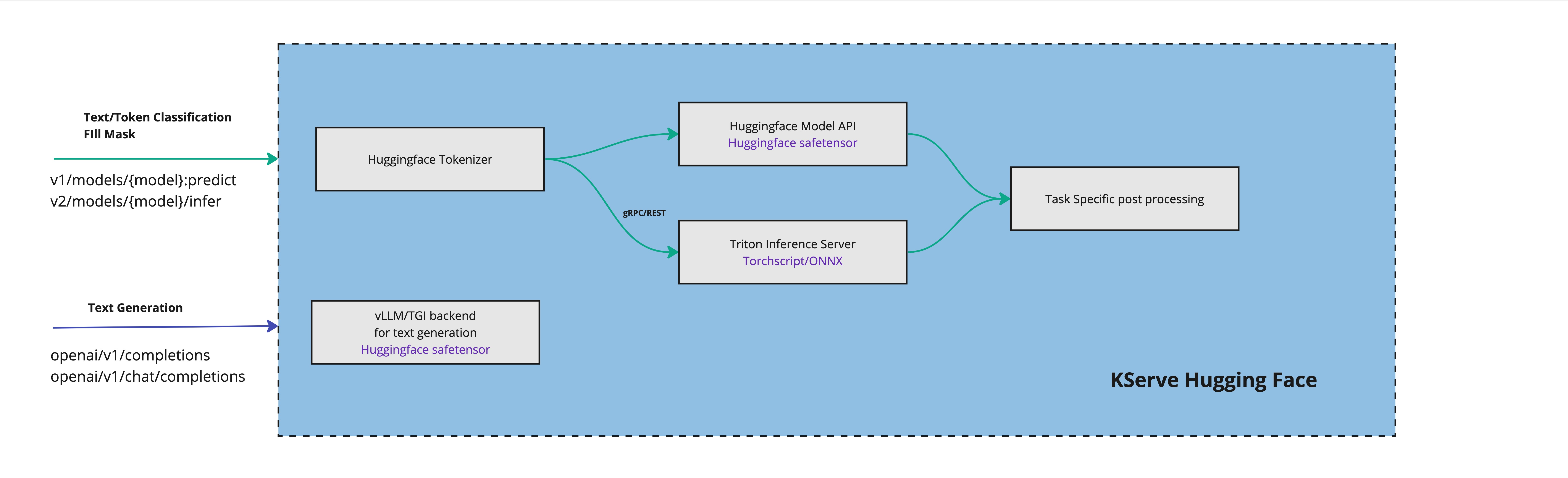
Here is an example to serve BERT model by deploying an Inference Service with Hugging Face runtime for classification task.
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: huggingface-bert
spec:
predictor:
model:
modelFormat:
name: huggingface
args:
- --model_name=bert
- --model_id=bert-base-uncased
- --tensor_input_names=input_ids
resources:
limits:
cpu: "1"
memory: 2Gi
nvidia.com/gpu: "1"
requests:
cpu: 100m
memory: 2Gi
nvidia.com/gpu: "1"
You can also deploy BERT on the more optimized inference runtime like Triton using Hugging Face Runtime for pre/post processing, see more details here.
🔧 vLLM Support
Version 0.13 introduces dedicated runtime support for vLLM, for enhanced transformer model serving. This support now includes auto-mapping vLLMs as the backend for supported tasks, streamlining the deployment process and optimizing performance. If vLLM does not support a particular task, it will default to the Hugging Face backend. See example below.
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: huggingface-llama3
spec:
predictor:
model:
modelFormat:
name: huggingface
args:
- --model_name=llama3
- --model_id=meta-llama/meta-llama-3-8b-instruct
resources:
limits:
cpu: "6"
memory: 24Gi
nvidia.com/gpu: "1"
requests:
cpu: "6"
memory: 24Gi
nvidia.com/gpu: "1"
See more details in our updated docs to Deploy the Llama3 model with Hugging Face LLM Serving Runtime.
Additionally, if the Hugging Face backend is preferred over vLLM, vLLM auto-mapping can be disabled with the --backend=huggingface arg.
🌐 OpenAI Schema Integration
Embracing the OpenAI protocol, KServe v0.13 now supports three specific endpoints for generative transformer models:
/openai/v1/completions/openai/v1/chat/completions/openai/v1/models
These endpoints are useful for generative transformer models, which take in messages and return a model-generated message output. The chat completions endpoint is designed for easily handling multi-turn conversations, while still being useful for single-turn tasks. The completions endpoint is now a legacy endpoint that differs with the chat completions endpoint in that the interface for completions is a freeform text string called a prompt. Read more about the chat completions and completions endpoints in the OpenAI API docs.
This update fosters a standardized approach to transformer model serving, ensuring compatibility with a broader spectrum of models and tools, and enhances the platform's versatility. The API can be directly used with OpenAI's client libraries or third-party tools, like LangChain or LlamaIndex.
🔮 Future Plan
- Support other tasks like text embeddings #3572.
- Support more LLM backend options in the future, such as TensorRT-LLM.
- Enrich text generation metrics for Throughput(tokens/sec), TTFT(Time to first token) #3461.
- KEDA integration for token based LLM Autoscaling #3561.
🛠️ Other Changes
This release also includes several enhancements and changes:
✨ What's New?
- Async streaming support for v1 endpoints #3402.
- Support for
.jsonand.ubjmodel formats in the XGBoost server image #3546. - Enhanced flexibility in KServe by allowing the configuration of multiple domains for an inference service #2747.
- Enhanced the manager setup to dynamically adapt based on available CRDs, improving operational flexibility and reliability across different deployment environments #3470.
⚠️ What's Changed?
🔍 Release Notes
For complete release notes including all changes, bug fixes, and known issues, visit the GitHub release page.
🙏 Acknowledgments
We want to thank all the contributors who made this release possible:
- Core Contributors: The KServe maintainers and regular as well as new contributors
- Community: Everyone who reported issues, provided feedback, and tested features
- Special Recognition: Contributors who helped drive the generative AI capabilities forward
🤝 Join the Community
- Visit our Website or GitHub
- Join the Slack (#kserve)
- Attend our community meeting by subscribing to the KServe calendar.
- View our community github repository to learn how to make contributions. We are excited to work with you to make KServe better and promote its adoption!
The KServe team is committed to making machine learning model serving simple, scalable, and standardized. Thank you for being part of our community!