Production-Grade LLM Inference at Scale with KServe, llm-d, and vLLM




Everyone is racing to run Large Language Models (LLMs), in the cloud, on-prem, and even on edge devices. The real challenge, however, isn't the first deployment; it's scaling, managing, and maintaining hundreds of LLMs efficiently. We initially approached this challenge with a straightforward vLLM deployment wrapped in a Kubernetes StatefulSet.
The Problem with "Simple" LLM Deployments
The approach quickly introduced severe operational bottlenecks:
- Storage Drag: Models like Llama 3 can easily reach hundreds of gigabytes in size. Relying on sluggish network storage (NFS) for these massive safetensors was a non-starter.
- Infrastructure Lock-in: Switching to local LVM persistent volumes solved the speed problem but created a rigid node-to-pod affinity. A single hardware failure meant a manual intervention to delete the Persistent Volume Claim (PVC) and reschedule the pod, which is an unacceptable burden for day-2 operations.
- Naive Load Balancing: Beyond the looming retirement of NGINX Ingress Controller, a simple round-robin load-balancing strategy is fundamentally inefficient for LLMs. It fails to utilize the critical KV-cache on the GPU, a core feature of vLLM that significantly boosts throughput. In a world where GPU costs are paramount, squeezing efficiency out of every core is non-negotiable.
What We Needed from an Operator
Running LLMs at scale demanded a purpose-built Kubernetes Operator designed for the intricacies of AI/ML. After evaluating the landscape, we identified a clear set of requirements:
- Full spec-level customization: We needed the ability to override the runtime specification beyond what typical Custom Resources expose — tailoring vLLM flags for specialized hardware and rapid iteration.
- Flexible deployment patterns: Rather than being locked into a single prefill/decode architecture, we needed an operator that could adapt to our evolving serving topologies.
- Standard Kubernetes API integration: The solution had to work with the Kubernetes API surface we already knew, not introduce an entirely new abstraction layer.
The Winning Combination: KServe + llm-d + vLLM
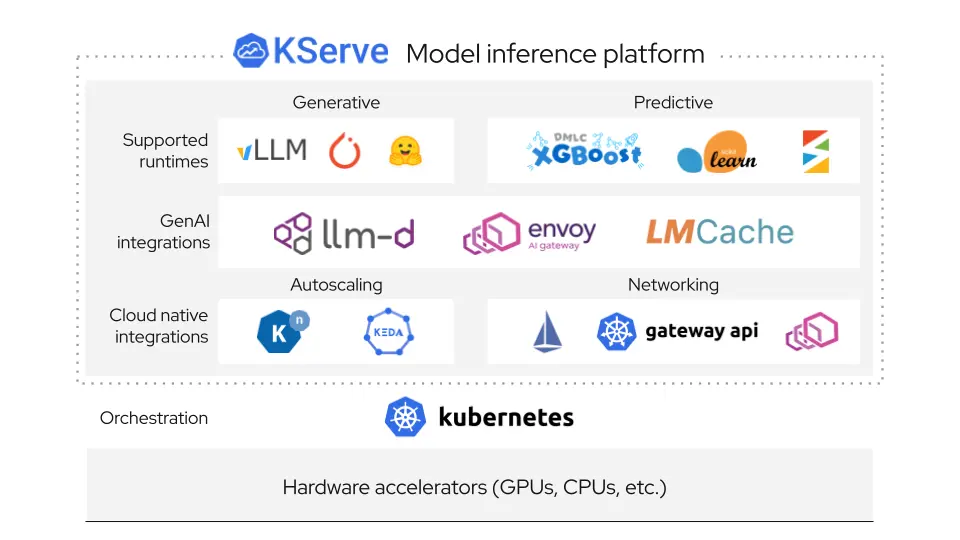
Our journey led us back to the most flexible and powerful solution: llm-d, powered by KServe and its cutting-edge Inference Gateway Extension.
This combination solved every scaling and operational challenge we faced by delivering:
- Deep Customization: The LLMInferenceService and LLMInferenceConfig objects expose the standard Kubernetes API, allowing us to override the spec precisely where needed. This level of granular control is crucial for tailoring vLLM to specialized hardware or quickly implementing flag changes.
- Intelligent Routing and Efficiency: By leveraging Envoy, Envoy AI Gateway, and Gateway API Inference Extension, we moved far beyond round-robin. This technology enables prefix-cache aware routing, ensuring requests are intelligently routed to the correct vLLM instance to maximize KV-cache utilization and drive up GPU efficiency.
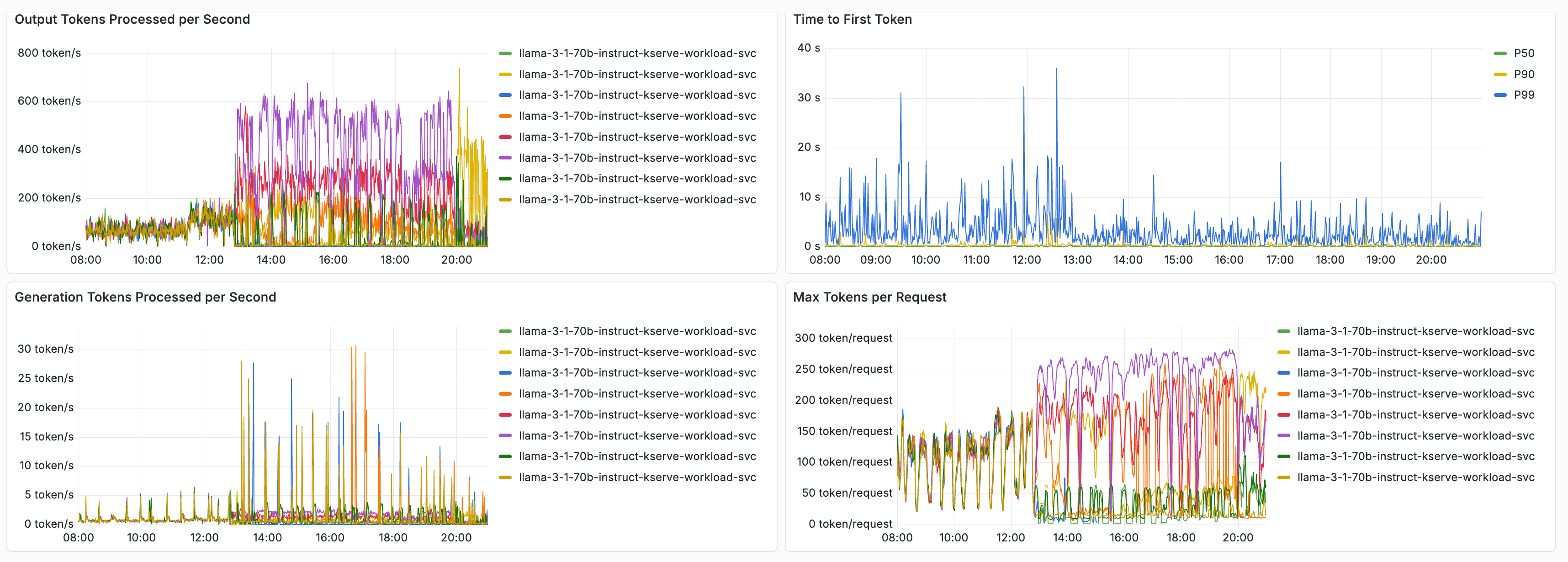
On one deployment, we observed a 3x improvement in output tokens/s and a 2x reduction in time to first token (TTFT) after enabling prefix-cache aware routing. These numbers were measured when serving Llama 3.1 70B model on 4 MI300X AMD GPUs with the configuration: tensor-parallel-size=4, gpu-memory-utilization=0.90, and --max-model-len=65536. Below is the chart that shows the performance improvement after we released the routing change (at around 12:30PM).
Community Contributions and Collaboration
Running this stack in production surfaced real issues that we fixed upstream in KServe, benefiting the broader community:
- New feature requests filed: #4901, #4900, #4898, #4899
- storageInitializer made optional (kserve#4970) — enabling RunAI Model Streamer as an alternative to the default storage initializer
- Added support for latest Gateway API Inference Extension (kserve#4886)
These contributions came directly from hitting production edge cases. Validating KServe and llm-d at this scale helped harden the platform for everyone running LLM workloads on Kubernetes.
Acknowledgement
We'd like to thank everyone from the community who has contributed to the successful adoption of KServe, llm-d, and vLLM in Tesla's production environment. In particular, below is the list of people from Red Hat and Tesla teams who have helped through the process (in alphabetical order).
- Red Hat team: Sergey Bekkerman, Nati Fridman, Killian Golds, Andres Llausas, Bartosz Majsak, Greg Pereira, Pierangelo Di Pilato, Ran Pollak, Vivek Karunai Kiri Ragavan, Robert Shaw, and Yuan Tang
- Tesla team: Scott Cabrinha and Sai Krishna
Get Involved with llm-d
The work described here is just one example of what becomes possible when a community of engineers tackles hard problems together in the open. If you're running LLMs at scale and wrestling with the same challenges — storage, routing, efficiency, day-2 operations — we'd love to have you involved.
- Explore the code → Browse our GitHub organization and dig into the projects powering this stack
- Join our Slack → Get your invite and connect directly with maintainers and contributors from Red Hat, Tesla, and beyond
- Attend community calls → All meetings are open! Add our public calendar (Wednesdays 12:30pm ET) and join the conversation
- Follow project updates → Stay current on Twitter/X, Bluesky, and LinkedIn
- Watch demos and recordings → Subscribe to the llm-d YouTube channel for community call recordings and feature walkthroughs
- Read the docs → Visit our community page to find SIGs, contribution guides, and upcoming events