LLMInferenceService Dependencies
Overview
LLMInferenceService requires several infrastructure components to function properly. This document explains each dependency, why it's needed, and how they work together.
Core Dependencies:
- Gateway API
- Gateway API Inference Extension (GIE)
- LeaderWorkerSet (LWS)
Dependency Overview Diagram
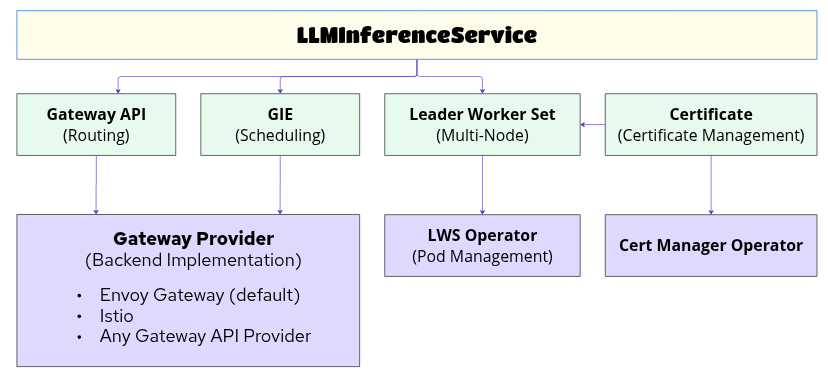
1. Gateway API
Purpose
Provides standardized ingress and routing capabilities for LLMInferenceService.
Why Required
- Standard API: Kubernetes-native way to define traffic routing
- Vendor-agnostic: Works with multiple backend providers (Envoy, Istio, etc.)
- Advanced Features: Path matching, header manipulation, timeouts, TLS termination
How LLMInferenceService Uses It
LLMInferenceService creates two core Gateway API resources:
- Gateway - Entry point for external traffic
- HTTPRoute - Routing rules from Gateway to backend services
2. Gateway API Inference Extension
Purpose
Extends Gateway API with LLM-specific scheduling and load balancing capabilities.
Why Required
- Intelligent Routing: Routes requests to optimal pods based on KV cache, load, and prefill-decode separation
- InferencePool: Represents a pool of inference pods with custom scheduling logic
- InferenceModel: Defines model metadata and criticality for scheduling decisions
How LLMInferenceService Uses It
LLMInferenceService creates GIE resources when scheduler is enabled.
Key Point: InferencePool has extensionRef pointing to the EPP (Endpoint Picker) service, which runs the scheduling logic.
3. LeaderWorkerSet
Purpose
Manages multi-node distributed inference workloads where multiple pods work together as a cohesive unit.
Why Required
- Unit of Replication: Ensures leader and worker pods are deployed together
- Network Identity: Maintains stable network identities for pod-to-pod communication
- Parallelism: Supports tensor parallelism, data parallelism, and expert parallelism
- RDMA Communication: Enables high-speed GPU-to-GPU communication across nodes
How LLMInferenceService Uses It
When spec.worker is present, LLMInferenceService creates a LeaderWorkerSet instead of a Deployment.
LWS Size Calculation (from spec.parallelism):
size = data / dataLocal
Example:
parallelism:
data: 8
dataLocal: 2
tensor: 4
Result: LWS Size = 8 / 2 = 4
→ 1 leader + 3 workers per replica
Real-world Example
"workload-dp-ep-gpu": {
"replicas": 2, # Number of LWS replicas
"parallelism": {
"data": 1,
"dataLocal": 8, # LWS size = 1/8 = 0.125, rounds to 1 (1 leader only)
"expert": True, # Expert parallelism enabled
"tensor": 1,
},
"template": { # Leader pod spec
"containers": [{
"resources": {
"limits": {"nvidia.com/gpu": "8"}
}
}]
},
"worker": { # Worker pod spec (triggers LWS creation)
"containers": [{
"resources": {
"limits": {"nvidia.com/gpu": "8"}
}
}]
}
}
4. Gateway Provider (Backend Implementation)
Purpose
Implements the Gateway API specification and routes traffic to backend services.
Why Multiple Providers?
Gateway API is a specification, not an implementation. The actual traffic routing is performed by a Gateway Provider (also called Gateway Controller).
Supported Providers
| Provider | Status | Features | Use Case |
|---|---|---|---|
| Envoy Gateway | Default | High performance, standard features | General purpose |
Installation Order: Critical Sequence
⚠️ Important: Install GIE CRDs BEFORE Gateway Provider
Why This Order Matters:
-
Gateway Provider Initialization: When a Gateway Provider (e.g., Envoy Gateway, Istio) starts, it scans for available CRDs to determine which extensions to support.
-
GIE Support: If GIE CRDs are installed after the Gateway Provider, the provider won't know about
InferencePoolandInferenceModelresources. -
Operator Restart Required: Installing GIE CRDs later requires restarting the Gateway Provider operator to detect the new CRDs.
Correct Installation Order
# Step 1: Install cert-manager (required by LWS)
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.17.0/cert-manager.yaml
# Step 2: Install Gateway API CRDs
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api/releases/download/v1.2.1/standard-install.yaml
# Step 3: Install GIE CRDs (BEFORE Gateway Provider!)
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/install.yaml
# Step 4: Install Gateway Provider (Envoy Gateway example)
helm install eg oci://docker.io/envoyproxy/gateway-helm \
--version v1.2.4 \
-n envoy-gateway-system --create-namespace
# Step 5: Install LWS Operator (if using multi-node)
kubectl apply -f https://github.com/kubernetes-sigs/lws/releases/download/v0.6.2/lws-operator.yaml
Verification:
# Check Gateway API CRDs
kubectl get crd | grep gateway.networking.k8s.io
# Check GIE CRDs
kubectl get crd | grep inference.networking
# Check LWS CRDs
kubectl get crd | grep leaderworkerset
# Check Gateway Provider is running
kubectl get pods -n envoy-gateway-system
kubectl get pods -n envoy-ai-gateway-system
Local Development: LoadBalancer Setup
Why LoadBalancer is Needed
Gateway API creates a Gateway resource with LoadBalancer service type to expose LLMInferenceService externally. Cloud platforms (AWS, GCP, Azure) provide LoadBalancer automatically, but local environments (kind, minikube) require manual setup.
Without LoadBalancer:
- Gateway service stays in
Pendingstate - External IP never assigned
- Cannot access LLMInferenceService from outside the cluster
Option 1: Using kind with cloud-provider-kind
cloud-provider-kind simulates cloud LoadBalancer by assigning IPs from Docker network.
# Create kind cluster
kind create cluster -n "kserve-llm"
# Install cloud-provider-kind
go install sigs.k8s.io/cloud-provider-kind@latest
# Run cloud-provider-kind in background
cloud-provider-kind > /dev/null 2>&1 &
Verification:
# Check Gateway service gets external IP
kubectl get gateway -A
kubectl get svc -A | grep LoadBalancer
How it works:
- Watches for LoadBalancer services
- Assigns IPs from Docker network range
- Makes Gateway accessible from host machine
Option 2: Using minikube with MetalLB
MetalLB provides LoadBalancer implementation for bare-metal clusters by allocating IPs from a configured range.
# Start minikube with sufficient resources
minikube start --cpus='12' --memory='16G' --kubernetes-version=v1.33.1
# Enable MetalLB addon
minikube addons enable metallb
# Configure IP address pool
IP=$(minikube ip)
PREFIX=${IP%.*}
START=${PREFIX}.200
END=${PREFIX}.235
kubectl apply -f - <<EOF
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- ${START}-${END}
EOF
Verification:
# Check MetalLB is running
kubectl get pods -n metallb-system
# Check Gateway service gets external IP from pool
kubectl get gateway -A
kubectl get svc -A | grep LoadBalancer
How it works:
- Allocates IPs from configured range (e.g., 192.168.49.200-235)
- Announces IPs using Layer 2 ARP
- Makes Gateway accessible from host machine
Option 3: Port Forwarding (Testing Only)
If LoadBalancer is not available, use port forwarding for quick testing:
# Forward Gateway service port
kubectl port-forward -n <namespace> svc/<gateway-service-name> 8080:80
# Access from localhost
curl http://localhost:8080/v1/completions ...
Limitations:
- Single terminal session (blocks)
- Not for production use
- No load balancing across replicas
Dependency Matrix
| Feature | Gateway API | GIE | LWS | Gateway Provider |
|---|---|---|---|---|
| Single-Node | ✅ | ✅ (scheduler) | ❌ | ✅ |
| Multi-Node | ✅ | ✅ (scheduler) | ✅ | ✅ |
| Prefill-Decode | ✅ | ✅ (required) | ❌ (single-node) or ✅ (multi-node) | ✅ |
| DP+EP | ✅ | ✅ (scheduler) | ✅ | ✅ |
| No Scheduler | ✅ | ❌ | ❌ | ✅ |