Understanding LLMInferenceService
What is LLMInferenceService?
LLMInferenceService is a Kubernetes Custom Resource Definition (CRD) introduced in KServe as part of its strategic shift towards GenAI-first architecture. Built on the foundation of llm-d—a production-ready framework for scalable LLM serving—LLMInferenceService delivers enterprise-grade capabilities for deploying and managing Large Language Model inference workloads on Kubernetes.
The llm-d project provides a proven architecture for high-performance LLM serving, combining vLLM's inference engine with Kubernetes orchestration and intelligent routing capabilities. Features like KV-cache aware scheduling, disaggregated prefill-decode serving, and distributed inference enable both optimal performance and cost efficiency. By integrating llm-d's architecture through a native Kubernetes CRD, KServe makes these advanced patterns accessible and easy to deploy, allowing users to achieve faster time-to-value while maintaining production-grade reliability.
Why a Separate CRD?
While KServe has traditionally used the InferenceService CRD for serving machine learning models (and it can still serve LLMs), KServe now adopts a dual-track strategy:
InferenceService: Optimized for Predictive AI workloads (traditional ML models like scikit-learn, TensorFlow, PyTorch)LLMInferenceService: Purpose-built for Generative AI workloads (Large Language Models)
This separation allows KServe to provide specialized features for LLM serving—such as distributed inference, prefill-decode separation, advanced routing, and multi-node orchestration—without adding complexity to the traditional InferenceService API.
Evolution: Dual-Track Strategy
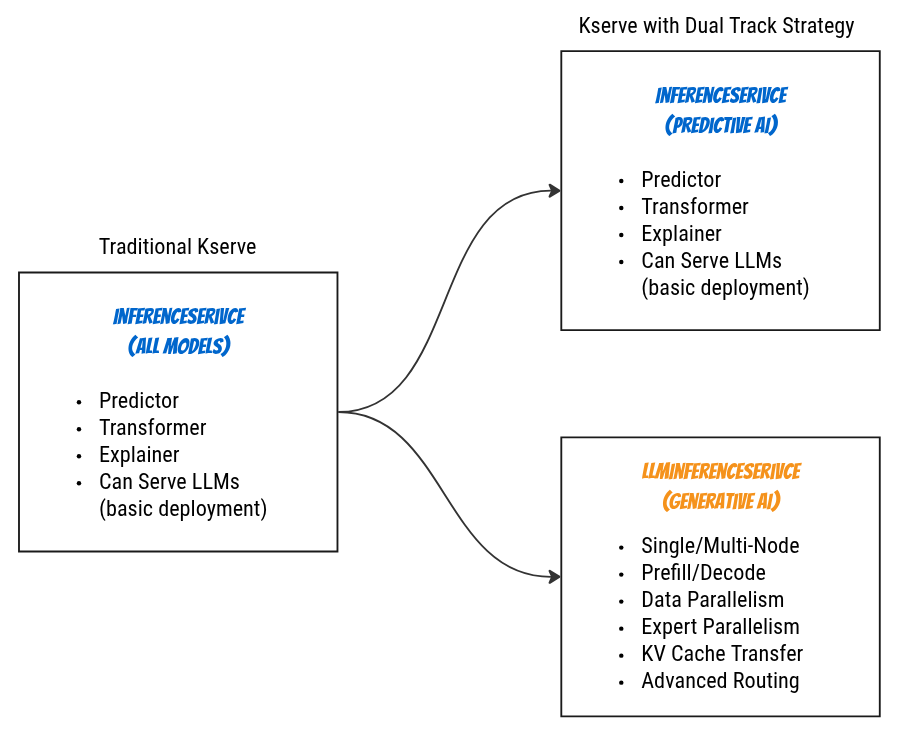
Strategic Separation:
- InferenceService: Remains the standard for Predictive AI (classification, regression, recommendations)
- LLMInferenceService: Dedicated to Generative AI with specialized optimizations
- Can you use InferenceService for LLMs? Yes, but only for basic single-node deployments. Advanced features like prefill-decode separation, multi-node orchestration, and intelligent scheduling are not available
Key Features
🎯 Composable Configuration
Mix and match LLMInferenceServiceConfig resources for flexible deployment patterns:
- Model configurations
- Workload templates
- Router settings
- Scheduler policies
Learn more: Config Composition Deep Dive
🚀 Multiple Deployment Patterns
- Single-Node: Simple deployments for small models (less than 7B parameters)
- Multi-Node: Distributed inference with LeaderWorkerSet for medium-large models
- Prefill-Decode: Disaggregated serving for cost optimization
- DP+EP: Data and Expert Parallelism for MoE models (Mixtral, DeepSeek-R1)
🌐 Advanced Routing
- Gateway API: Standard Kubernetes ingress
- Intelligent Scheduling: KV cache-aware, load-balanced routing
- Prefill-Decode Separation: Automatic routing to optimal pools
⚡ Distributed Inference
- Tensor Parallelism (TP): Split model layers across GPUs
- Data Parallelism (DP): Replicate models for throughput
- Expert Parallelism (EP): Distribute MoE experts across nodes
🔧 Production-Ready
- RBAC and authentication
- Model storage integration (HuggingFace, S3, PVC)
- KV cache transfer via RDMA
- Monitoring and metrics
When to Use LLMInferenceService
| Scenario | Use LLMInferenceService? | Why? |
|---|---|---|
| Serving LLMs (7B-405B params) | ✅ Yes | Optimized for LLM workloads |
| Multi-GPU inference | ✅ Yes | Built-in parallelism support |
| High throughput requirements | ✅ Yes | Prefill-decode separation, intelligent routing |
| Traditional ML models | ❌ No | Use InferenceService instead |
| Small models (less than 70B params) | 🟡 Optional | Either works, but LLMInferenceService offers more features |
High Level Architecture Overview
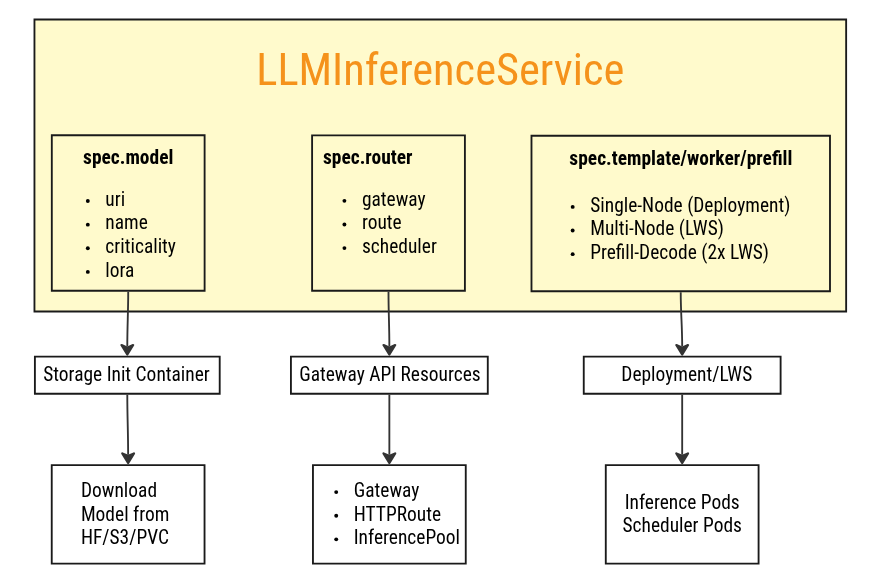
Core Components at a Glance
1. Model Specification (spec.model)
Defines the LLM model source, name, and characteristics:
- Model URI (HuggingFace, S3, PVC)
- Model name for API requests
- Scheduling criticality
- LoRA adapters (optional) - Attach task-specific Low-Rank Adaptation modules for efficient multi-tenant serving
Learn more: Configuration Guide | LoRA Adapters
2. Workload Specification
Defines compute resources and deployment patterns:
spec.template: Single-node or decode workloadspec.worker: Multi-node workers (triggers LeaderWorkerSet)spec.prefill: Prefill-only workload (disaggregated)
Learn more: Configuration Guide
3. Router Specification (spec.router)
Defines traffic routing and load balancing:
- Gateway: Entry point for external traffic
- HTTPRoute: Path-based routing rules
- Scheduler: Intelligent endpoint selection (EPP)
Learn more: Architecture Guide
4. Parallelism Specification (spec.parallelism)
Defines distributed inference strategies:
- Tensor Parallelism (TP)
- Data Parallelism (DP)
- Expert Parallelism (EP)
Learn more: Configuration Guide
Quick Example
Here's a minimal LLMInferenceService for serving Llama-3.1-8B:
apiVersion: serving.kserve.io/v1alpha1
kind: LLMInferenceService
metadata:
name: llama-3-8b
namespace: default
spec:
model:
uri: hf://meta-llama/Llama-3.1-8B-Instruct
name: meta-llama/Llama-3.1-8B-Instruct
replicas: 3
template:
containers:
- name: main
image: vllm/vllm-openai:latest
resources:
limits:
nvidia.com/gpu: "1"
cpu: "8"
memory: 32Gi
router:
gateway: {} # Managed gateway
route: {} # Managed HTTPRoute
scheduler: {} # Managed scheduler
What this creates:
- 3 replica pods with 1 GPU each
- Gateway API ingress
- Intelligent scheduler for load balancing
- Storage initializer for model download
Documentation Map
This overview provides a high-level introduction to LLMInferenceService. For detailed information, explore the following guides:
📚 Core Concepts
- Configuration Guide: Detailed spec reference and configuration patterns
- Architecture Guide: System architecture and component interactions
- Dependencies: Required infrastructure components
🔧 Advanced Topics
- Autoscaling with WVA: Inference-aware autoscaling using the Workload Variant Autoscaler
- Scheduler Configuration: Prefix cache routing, load-aware scheduling
- Multi-Node Deployment: LeaderWorkerSet, RDMA networking
- Security: Authentication, RBAC, network policies
Summary
LLMInferenceService provides a comprehensive, Kubernetes-native approach to LLM serving with:
- ✅ Composable Configuration: Mix and match configs for flexible deployment
- ✅ Multiple Workload Patterns: Single-node, multi-node, prefill-decode separation
- ✅ Advanced Routing: Gateway API + intelligent scheduler
- ✅ Distributed Inference: Tensor, data, and expert parallelism
- ✅ Production-Ready: Monitoring, RBAC, storage integration, KV cache transfer
This architecture enables organizations to deploy and scale LLM inference workloads efficiently on Kubernetes, with the flexibility to optimize for different model sizes, hardware configurations, and performance requirements.