Highly scalable and standards based
Model Inference Platform on Kubernetes
for Trusted AI

Why KServe?
- KServe is a standard Model Inference Platform on Kubernetes, built for highly scalable predictive and generative inference.
- Provides performant, standardized inference protocol across ML frameworks.
- Support modern serverless inference workload with Autoscaling including Scale to Zero on GPU.
- Provides high scalability, density packing and intelligent routing using ModelMesh
- Simple and Pluggable production serving for production ML serving including prediction, pre/post processing, monitoring and explainability.
- Advanced deployments with canary rollout, experiments, ensembles and transformers.
KServe Components

Provides Serverless deployment for model inference on CPU/GPU with common ML frameworks
Scikit-Learn,
XGBoost,
Tensorflow,
PyTorch,
Hugging Face as well as pluggable custom model runtime.
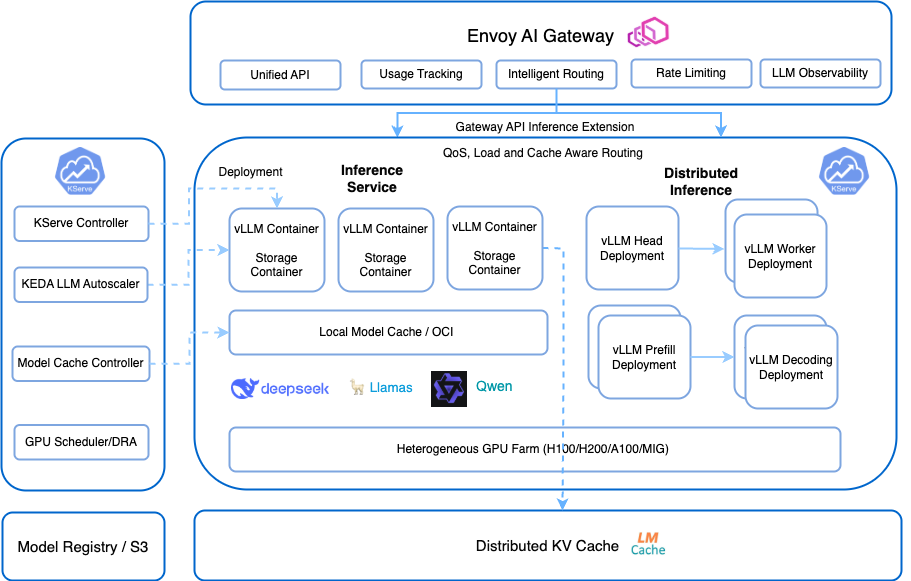
Provides scalable, low latency serving for large language models through vLLM integration, distributed KV cache and LLM metrics based autoscaling.
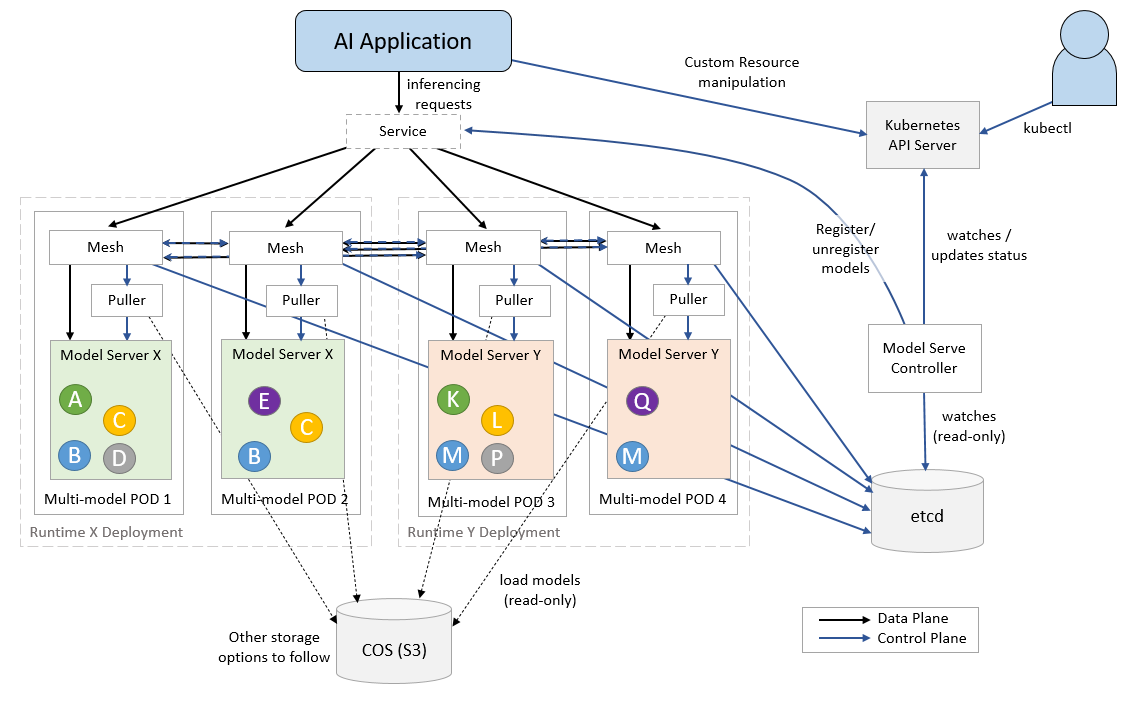
ModelMesh is designed for high-scale, high-density and frequently-changing model use cases. ModelMesh
intelligently loads and unloads AI models to and from memory to strike an intelligent trade-off
between responsiveness to users and computational footprint.
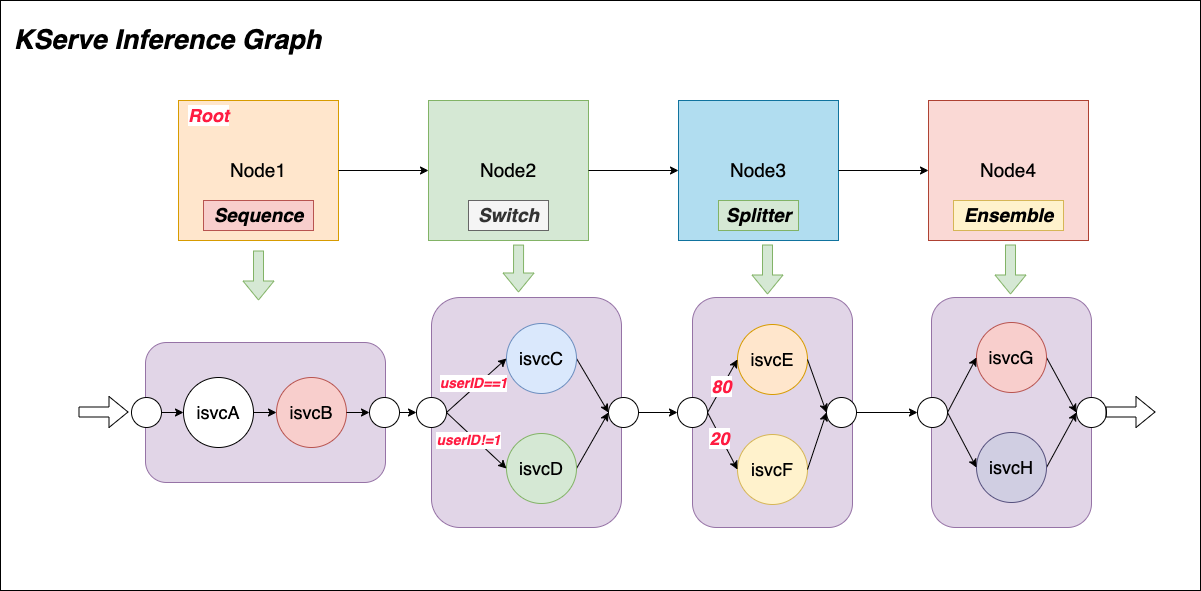
KServe inference graph supports four types of routing node: Sequence, Switch, Ensemble, Splitter.
Enables payload logging, outlier, adversarial and drift detection, KServe integrates
AI Fairness 360,
Adversarial Robustness Toolbox (ART) to help monitor the ML models on production.
Provides ML model inspection and interpretation, KServe integrates Captum
to help explain the predictions and gauge the confidence of those predictions.
Adopters





..and more!